
















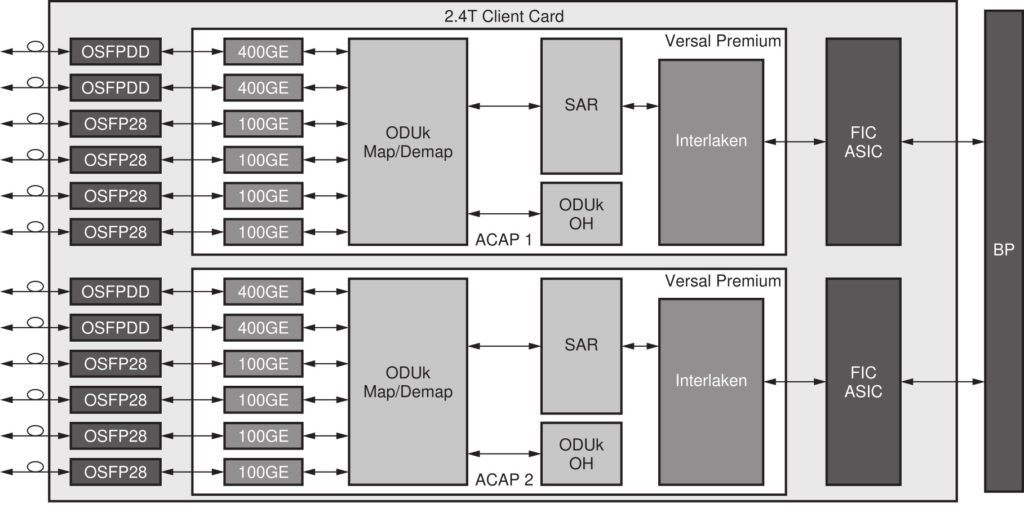
このデバイスは、Versal プレミアム ACAP を利用してデジタル トラフィックとサービスをブリッジし、業界標準の OTN ラッパーにカプセル化することで、高速クライアント インターフェイス カードにも最適です (図 3)。統合されたチャネライズド イーサネット、Interlaken、112G および 58G PAM4 GTM トランシーバー、32.75G GTYP トランシーバーは、1 秒あたり数テラビットを提供します。専用ハード IP として統合されたこれらのリソースは、ASIC クラスの電力効率を実現すると同時に、ACAP ロジック ファブリックをマッピング、オーバーヘッド、SAR 機能のために使用できるようにします。
未来を見据えた AI アクセラレーション
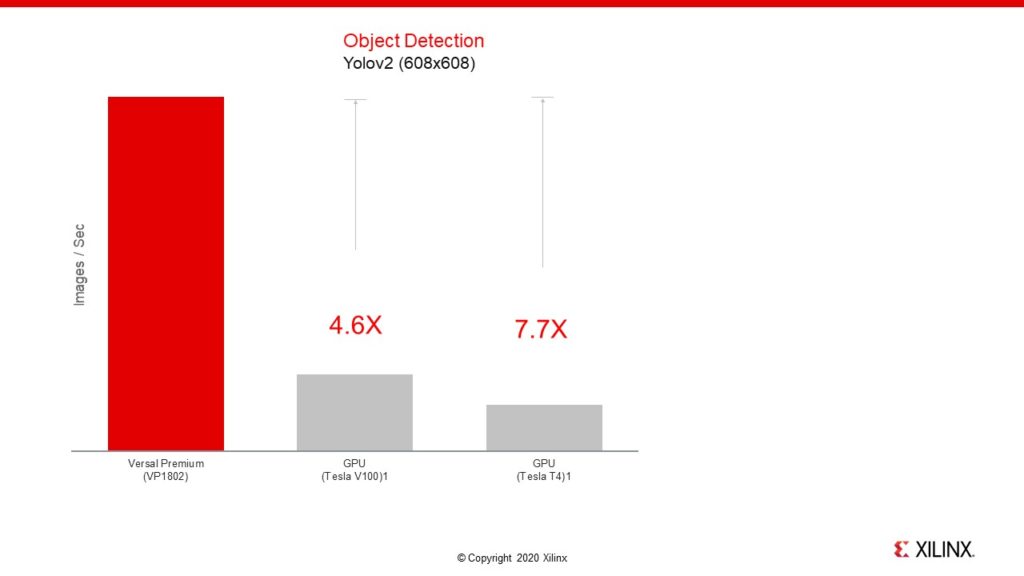
ヘテロジニアス演算エンジンと高いメモリ帯域幅を組み合わせた Versal プレミアム ACAP は、画像分類やニューラル ネットワークでのオブジェクト検出といった高度なワークロードを処理する際に、GPU を大きく上回るパフォーマンスを発揮します。図 4 は主要 GPU とのパフォーマンス比較で、680×680 の YOLOv2 モデルで実行されるオブジェクト検出を、ACAP プレミアム デバイスでは 7.7 倍も高速化できることを示しています。
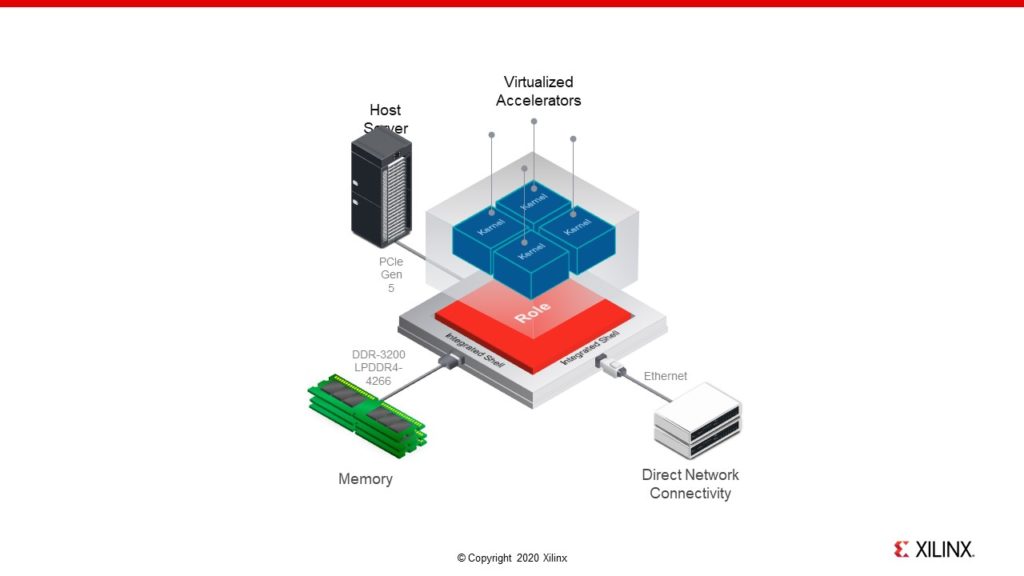
FPGA や MPSoC アーキテクチャと比較してアクセラレーター開発を容易にする ACAP のもう 1 つの興味深い特長は、イーサネット、PCIe Gen 5、DDR4、光インターフェイスなどのオフチップ インターフェイスとのハード接続を可能にするシェルが事前に組み込まれていることです (図 5)。この効率的なクラウド接続のためのインフラストラクチャは、CPU ホストとシステムのメモリ通信をデバイス始動時から使用できる、カーネルの配置とタイミング クロージャを簡素化できる、アクセラレーターの仮想化を簡素化できるなどの利点を提供します。このシェルにより、メモリや DMA コントローラーなどの必要なインフラストラクチャの実装にデバイスの内部ロジック ファブリックが不要になり、設計者はこのリソースをカスタム機能のためにより多く利用できるようになります。
シェルとロール アーキテクチャは、設計者が高度なスマート リテール テクノロジを Versal プレミアム ACAP にすばやく効率的に実装するのに役立ちます。このデバイスはデータ駆動型のビデオ コンテンツ分析をサポートして、ロスを軽減し、在庫に関する実用的なインサイトをリアルタイムで自動提供するだけでなく、カスタマー エクスペリエンスを調整して売上を最大限に高めることを可能にします。Versal プレミアム ACAP を利用すると、1 つのプラットフォームでビデオ メタデータの識別、抽出、分類が可能なビデオ分析ソリューションをホストできます (図 6)。
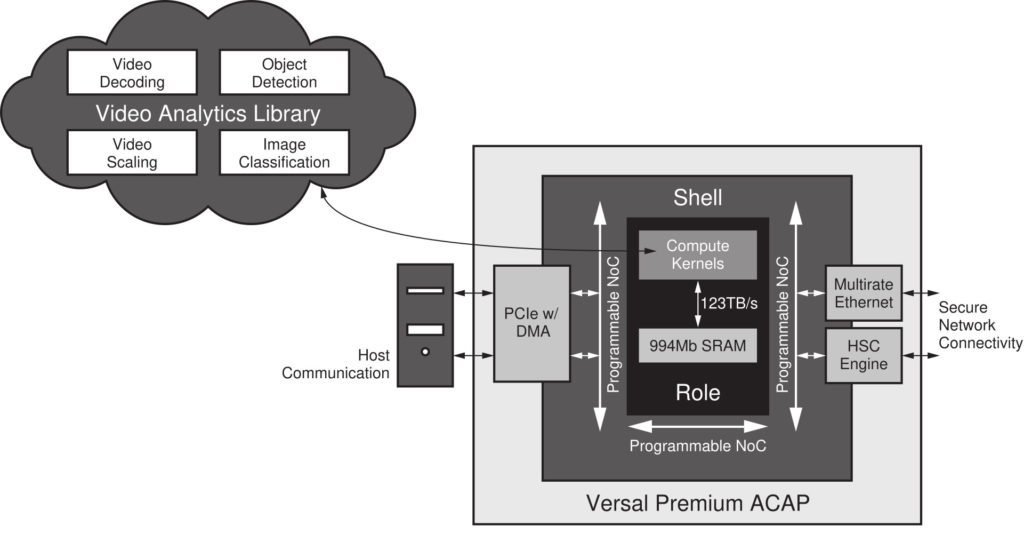
シェルにはコネクティビティと暗号化機能があらかじめ備わっており、一方デバイスの DSP エンジンとソフトウェア プログラマブル演算カーネルはオブジェクト検出と画像分類に加え、ビデオ エンコーディング、デコーディング、スケーリングも行います。最大 1Gb のオンチップ SRAM は演算カーネルに隣接しており、AI アクセラレーション用に最大 123TB/s のメモリ帯域幅を提供します。GPU や CPU ベースのアーキテクチャの妨げとなっているメモリ ボトルネックとバッチ サイズ制限がないため、アナリティクス アクセラレーターは Resnet50 の場合で最大 13,000 イメージ/秒で動作できます。
結論
消費者向けであれビジネス向けであれ、データ中心の世界はますます広がっており、そこに必要とされる演算がどんなに複雑で膨大でも、帯域幅を消費しても、利用者はますます迅速なサービスを求めています。ACAP は、効率的な分散型ヘテロジニアス演算エンジンと高速インターコネクトを兼ね備え、急激に高まっているパフォーマンス要件に対応します。ハード IP、革新的な構築済みのコネクティビティ シェル、プログラマブル ロジック ファブリック、ソフトウェア構築可能なリソースを搭載したこのデバイスは、パフォーマンスを大幅に向上させるだけでなく、設計を簡素化して、将来を見据えた製品を可能にする柔軟性を提供します。
Xilinx
関連記事一覧

Arm Chinaの反体制CEO、Nvidiaの買収破綻はArmと 「中...

BBバックボーン の新しい伝送サービス「B³Spectrum 400...

AlibabaがAI推論チップを開発~Nvidia H20の輸出停滞が...

TencentがAI、ビデオトランスコーディング、ネットワー...

JDCC「第15回業界コミュニティ」開催のご案内

簡単に組み立てられるモジュラー型アイルコンテインメ...

キヤノンが同社初のナノインプリント半導体製造装置を...

TSMCが2030年までに台湾の電力消費量の24%を占める可能性

Google 、AIチップ特許侵害の疑いで16.7億ドルの訴訟を...

ArmサーバーチップのAmpere Computing社が売却を検討中

Tata Group、インドに3億ドル規模の半導体組立・テスト...

データセンターインフラ運用の省人化と省エネ化を支援...

米国初のNvidia Blackwellウェハー、TSMCアリゾナ工場...

SKハイニックス、韓国の新チップ工場と2022年以来の黒...

TSMCが台湾に2つのチップ工場を追加建設へ
コメント ( 0 )
トラックバックは利用できません。
この記事へのコメントはありません。