















【原文著者】アンディ・ローレンス氏 Uptime Institute社
障害によるデータセンターの停止問題がより深刻になっているようです。しかし、なぜ停止時間は長くなっているのでしょうか?
Uptime Instituteが最近発行したレポート「2020年の年間停止分析」での調査結果で分かったことの1つは、サービスの重大な中断を引き起こす”最も深刻な停止”のカテゴリが、より深刻かつコストが高くなっている、ということです。これはまったく驚くべきことではありません。今や個人も企業も同様、ITへの依存が高まり、ITサービスを手動のシステムに複製したり置き換えたりすることが難しくなっています。
しかし、分かったことの一つは危険信号と質問を提起しています。部分的かつ偶発的なもの(影響が最小限であったもの)を別にすれば、過去3年間に公式に報告された停止は時間が長くなっているようです。そしてこれが、停止のコストと重大性を上昇させている理由の1つであると思われます。
この表は、2017年から2019年にUptime Instituteによって収集された、公式に報告された停止の数を示しています。但し、金銭的あるいは顧客への影響を与えなかった停止、または既知の原因では無かった停止を除きます。図では、停止障害が増加していることを示しています。これは、ITサービス導入の拡大や報告の改善など、いくつかの要因によるものであると思われます。しかし、より長い停止時間、特に48時間以上続いた停止が増加しているという傾向も同時に示しています。(これは、長時間の停止につながる最大の原因の1つであるランサムウェア要因がサンプルから除外されていたとしても当てはまります。)
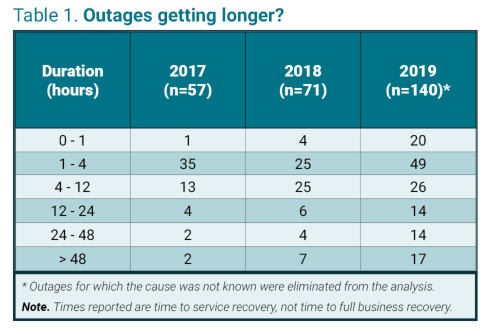
Uptime Institute:年間停止分析2020 より
– Uptime Institute
報告された停止時間は、事業的な回復ではなくITサービスの完全回復まで、を意味しています。例えば、航空機を本来の場所に戻すことと、あるいは保険金請求の未処理に対処するという違いと同様、事業の回復にはさらに時間がかかる場合があります。
長時間停止の傾向は劇的なものではありませんが、多くの組織にとって48時間もの中断は致命的となる可能性があり、問題は現実的であり懸念されます。
なぜそれが起こっているのでしょうか?ITシステムの複雑さと相互依存性、およびソフトウェアやデータへのより大きな依存性が大きな理由の可能性が非常に高いです。たとえば、 Uptime Institute の調査によると、大規模な停止障害はデータセンターの停電によるものではなく、ITシステムの構成に関係するものが過去よりも多くなっています。施設の技術的な問題の解決は簡単ではないかもしれませんが、通常は比較的予測可能な問題です。障害の原因は多くの場合バイナリ(=二択)であり、多くの場合、復旧手順はオペレータに叩き込まれており、スペアパーツは手元にあります。しかしながら、ソフトウェア、データの整合性、および組織間のビジネスプロセスの破損/中断は、解決が難しい場合があり、診断することさえ難しい場合があります。そして、このような種類の障害はより一般的になりつつあります。(そして、はい、時々それらの障害は電源障害に起因し、引き起こされています)更にいうならば、障害が部分的なものであっても、ファイルが同期しなくなったり、破損する可能性さえあります。
描けるレッスンがあります。最も大きなものは、施設のスタッフが30年以上にわたり生かしてきたレジリエンス体制を拡張し、ITや DevOps に統合し、経営側が完全にサポート・投資していく必要があるということです。もう1つは、商用バックアップサービスの一種としての災害復旧(ディザスタリカバリ)が徐々に消えつつある一方で、警戒( vigilance )、復旧( recovery )、およびフェールオーバー( fail over )の原則(特にストレスがかかっている場合)がこれまで以上に重要になっているということです。
Data Center Dynamics
完全なレポート(英語)の入手先リンクはこちらから(注:Uptimeサイトへのメンバー登録が必要です)
関連記事一覧

日本のデータセンター市場の成長をナビゲートする【特集】
ジェネレーティブAIとデータセンターの未来: パート3 ...

新型コロナとeコマースブームが招いた一等地をめぐる競...
ハイパースケールデータセンターとは?【特集】

「お持ち帰り」エッジデータセンター【特集】

現代のITインフラを支えるデータセンター物理インフラ...

車から車へ、Driving Transport Edge【特集】

【特集記事】データセンター設計に関する6つの重要な考...
【特集記事】小売業の変革 – データが及ぼす影響
海底ケーブルとは?海底光ファイバーについて解説【特集】

世界のデータセンターの再エネ対応状況まとめ【特集】

データセンターインフラ運用の省人化と省エネ化を支援...

【特集記事】2020年のクラウドを定義する重要なトレンド

エッジが道路にぶつかる【特集】
データセンターとは?【特集】
コメント ( 0 )
トラックバックは利用できません。
この記事へのコメントはありません。